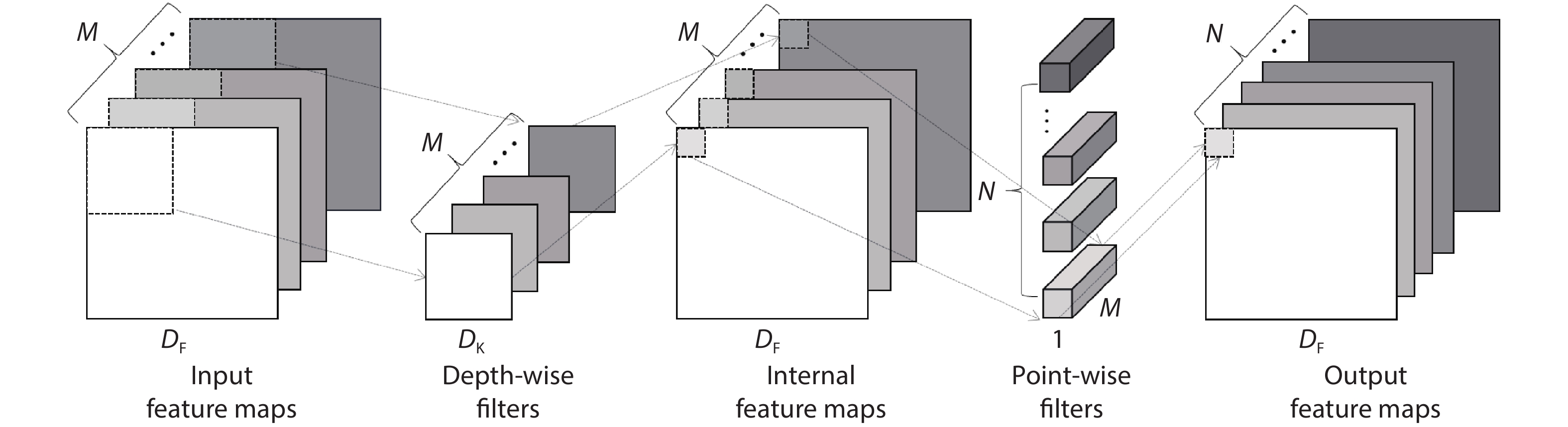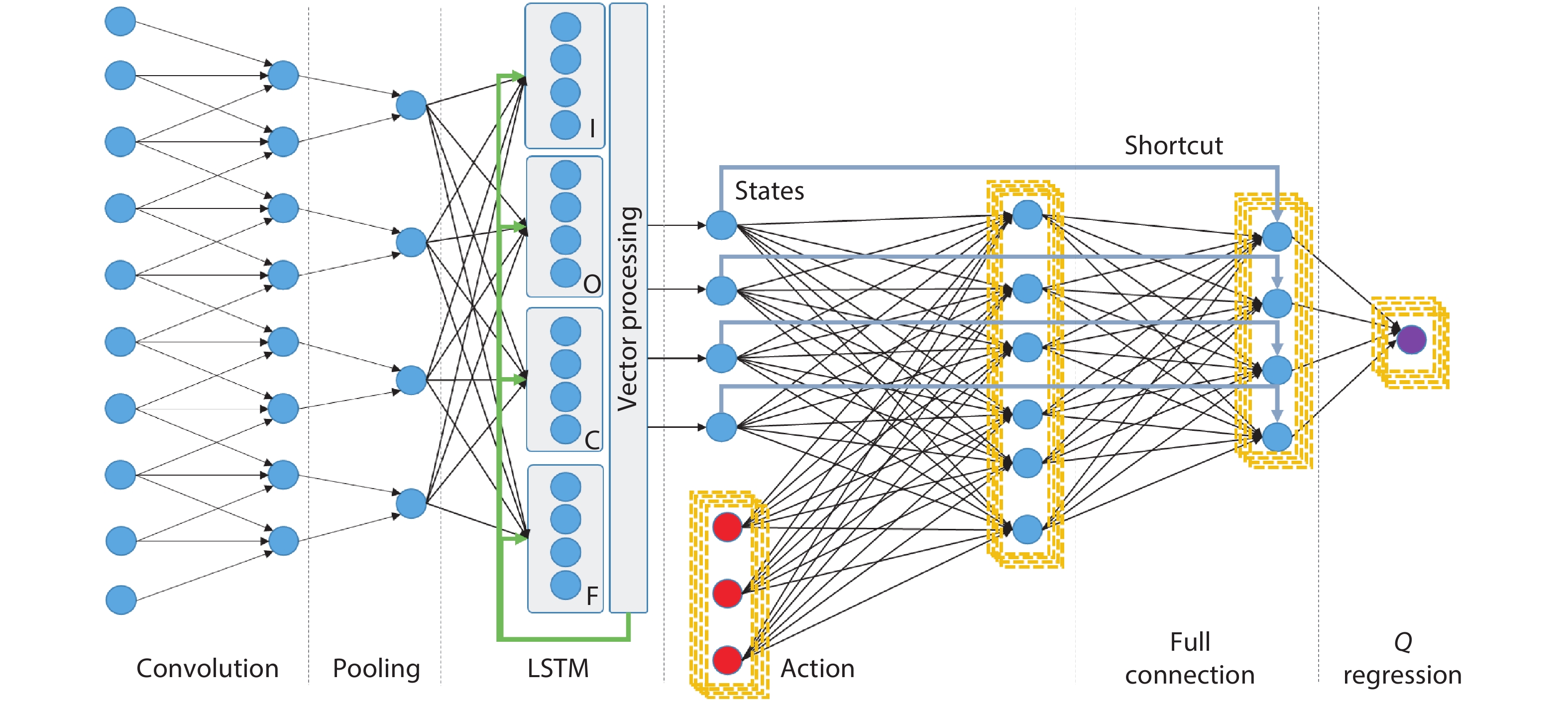
Fig. 1.
(Color online) Structure of hybrid neural network targeting perception and control with layer-wise algorithmic kernels.
ARTICLES
Zheng Wang1, , Libing Zhou2, Wenting Xie2, Weiguang Chen1, Jinyuan Su2, Wenxuan Chen2, Anhua Du2, Shanliao Li3, Minglan Liang3, Yuejin Lin2, Wei Zhao2, Yanze Wu4, Tianfu Sun1, Wenqi Fang1 and Zhibin Yu1
Corresponding author: Zheng Wang, Email: zheng.wang@siat.ac.cn
Abstract: Driven by continuous scaling of nanoscale semiconductor technologies, the past years have witnessed the progressive advancement of machine learning techniques and applications. Recently, dedicated machine learning accelerators, especially for neural networks, have attracted the research interests of computer architects and VLSI designers. State-of-the-art accelerators increase performance by deploying a huge amount of processing elements, however still face the issue of degraded resource utilization across hybrid and non-standard algorithmic kernels. In this work, we exploit the properties of important neural network kernels for both perception and control to propose a reconfigurable dataflow processor, which adjusts the patterns of data flowing, functionalities of processing elements and on-chip storages according to network kernels. In contrast to state-of-the-art fine-grained data flowing techniques, the proposed coarse-grained dataflow reconfiguration approach enables extensive sharing of computing and storage resources. Three hybrid networks for MobileNet, deep reinforcement learning and sequence classification are constructed and analyzed with customized instruction sets and toolchain. A test chip has been designed and fabricated under UMC 65 nm CMOS technology, with the measured power consumption of 7.51 mW under 100 MHz frequency on a die size of 1.8 × 1.8 mm2.
Key words: CMOS technology, digital integrated circuits, neural networks, dataflow architecture
| [1] |
Chen Y, Krishna T, Emer J, et al. Eyeriss: An energy-efficient reconfigurable accelerator for deep convolutional neural networks. IEEE J Solid-State Circuits, 2017, 52, 127 doi: 10.1109/JSSC.2016.2616357
|
| [2] |
Jouppi N, Young C, Patil N, et al. In-datacenter performance analysis of a tensor processing unit. ACM/IEEE International Symposium on Computer Architecture, 2017, 1
|
| [3] |
Chen Y, Tao L, Liu S, et al. DaDianNao: A machine-learning supercomputer. ACM/IEEE International Symposium on Microarchitecture, 2015, 609
|
| [4] |
Cong J, Xiao B. Minimizing computation in convolutional neural networks. Artificial Neural Networks and Machine Learning, 2014, 281
|
| [5] |
Yin S, Ouyang P, Tang S, et al. A high energy efficient reconfigurable hybrid neural network processor for deep learning applications. IEEE J Solid-State Circuits, 2017, 53, 968 doi: 10.1109/JSSC.2017.2778281
|
| [6] |
Russakovsky O, Deng J, Su H, et al. ImageNet large scale visual recognition challenge. Int J Comput Vision, 2015, 115, 211 doi: 10.1007/s11263-015-0816-y
|
| [7] |
Iandola F, Han S, Moskewicz M, et al. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and < 0.5 MB model size. arXiv: 1602.07360, 2016
|
| [8] |
Howard A, Zhu M, Chen B, et al. MobileNets: Efficient convolutional neural networks for mobile vision applications. arXiv: 1704.04861, 2017
|
| [9] |
Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014,
|
| [10] |
Yang C, Wang Y, Wang X, et al. A reconfigurable accelerator based on fast winograd algorithm for convolutional neural network in internet of things. IEEE International Conference on Solid-State and Integrated Circuit Technology, 2018, 1
|
| [11] |
Vasilache N, Johnson J, Mathieu M, et al. Fast convolutional nets with fbfft: A GPU performance evaluation. arXiv: 1412.7580, 2014
|
| [12] |
Guo K, Zeng S, Yu J, et al. A survey of FPGA-based neural network accelerator. arXiv: 1712.08934, 2017
|
| [13] |
Mnih V, Kavukcuoglu K, Silver D, et al. Playing atari with deep reinforcement learning. arXiv: 1312.5602, 2013
|
| [14] |
Mnih V, Kavukcuoglu K, Silver D, et al. Human-level control through deep reinforcement learning. Nature, 2015, 518, 529 doi: 10.1038/nature14236
|
| [15] |
Silver D, Huang A, Maddison C, et al. Mastering the game of Go with deep neural networks and tree search. Nature, 2016, 529, 484 doi: 10.1038/nature16961
|
| [16] |
Silver D, Schrittwieser J, Simonyan K, et al. Mastering the game of Go without human knowledge. Nature, 2017, 550, 354 doi: 10.1038/nature24270
|
| [17] |
Chen Y, Emer J, Sze V. Eyeriss: A spatial architecture for energy-efficient dataflow for convolutional neural networks. ACM/IEEE International Symposium on Computer Architecture, 2016, 44, 367
|
| [18] |
Gers F, Schmidhuber J, Cummins F. Learning to forget: Continual prediction with LSTM. 9th International Conference on Artificial Neural Networks, 1999, 850 doi: 10.1049/cp:19991218
|
| [19] |
Basterretxea K, Tarela J, Del C. Approximation of sigmoid function and the derivative for hardware implementation of artificial neurons. IEE Proc Circuits, Devices Syst, 2004, 151, 18
|
| [20] |
Sutton R, Barto A. Reinforcement learning: An introduction. MIT Press, 2018
|
| [21] |
Gulli A, Sujit P. Deep learning with Keras. Packt Publishing Ltd, 2017
|
| [22] |
Li S, Ouyang N, Wang Z. Accelerator design for convolutional neural network with vertical data streaming. IEEE Asia Pacific Conference on Circuits and Systems, 2018, 544
|
| [23] |
Guo Y. Fixed point quantization of deep convolutional networks. International Conference on Machine Learning, 2016, 2849
|
| [24] |
Opalkelly product manual. https://opalkelly.com/products/frontpanel
|
| [25] |
Chen W, Wang Z, Li S, et al. Accelerating compact convolutional neural networks with multi-threaded data streaming. IEEE Computer Society Annual Symposium on VLSI, 2019, 519
|
| [26] |
MitchellSpryn solving a maze with Q learning. www.mitchellspryn.com/2017/10/28/Solving-A-Maze-With-Q-Learning.html
|
| [27] |
Liang M, Chen M, Wang Z. A CGRA based neural network inference engine for deep reinforcement learning. IEEE Asia Pacific Conference on Circuits and Systems, 2018, 519
|
| [28] |
Chen Y, Krishna T, Emer J, et al. Eyeriss: An energy-efficient reconfigurable accelerator for deep convolutional neural networks. IEEE International Solid-State Circuits Conference (ISSCC), 2016, 127
|
| [29] |
Moons B, Uytterhoeven R, Dehaene W, et al. ENVISION: A 0.26-to-10 TOPS/W subword-parallel dynamic-voltage-accuracy-frequency-scalable convolutional neural network processor in 28 nm FDSOI. IEEE International Solid-State Circuits Conference (ISSCC), 2017, 246
|
| [30] |
Yin S, Ouyang P, Tang S, et al. 1.06-to-5.09 TOPS/W reconfigurable hybrid-neural-network processor for deep learning applications. Symposium on VLSI Circuits, 2017
|
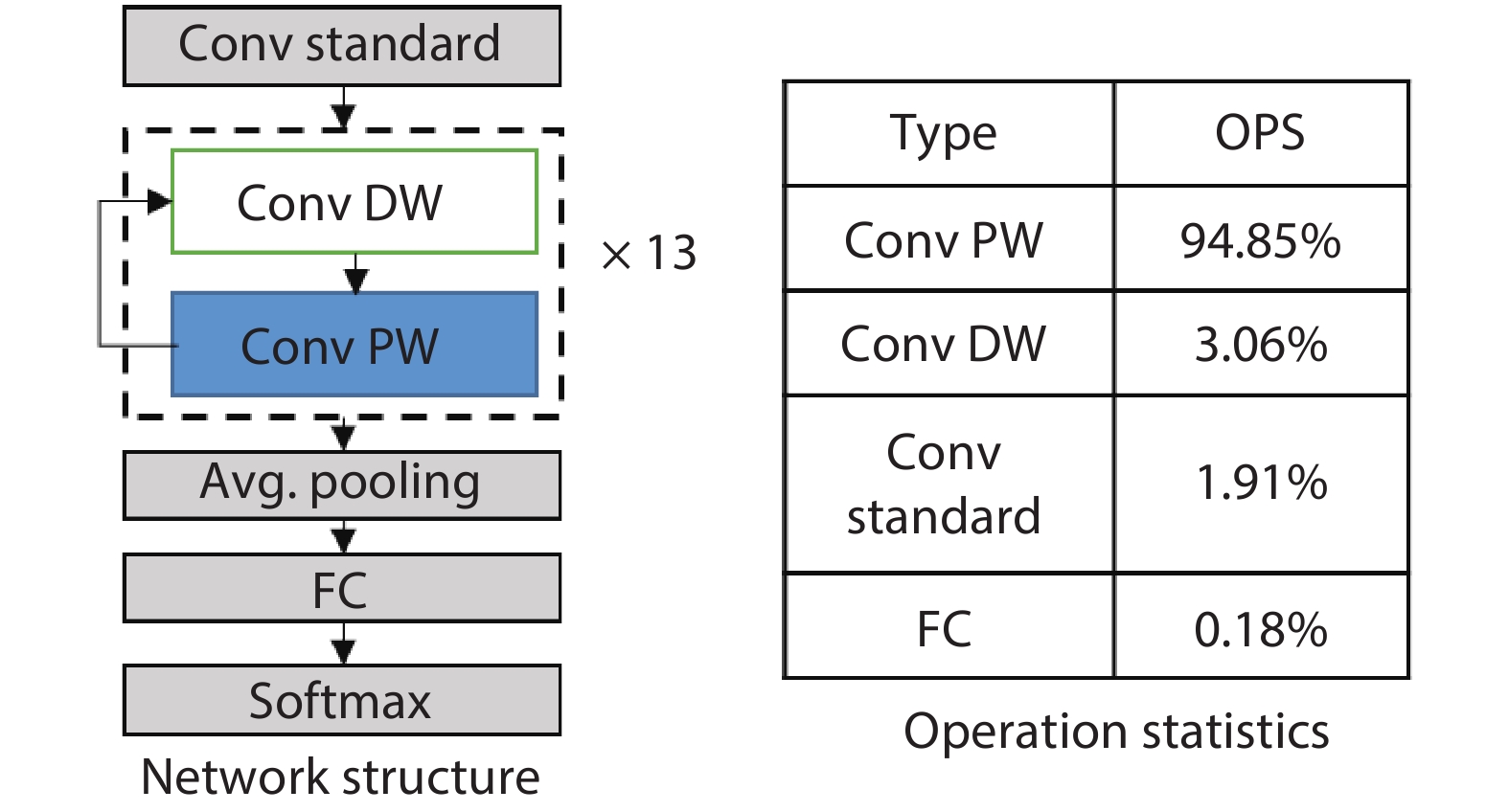
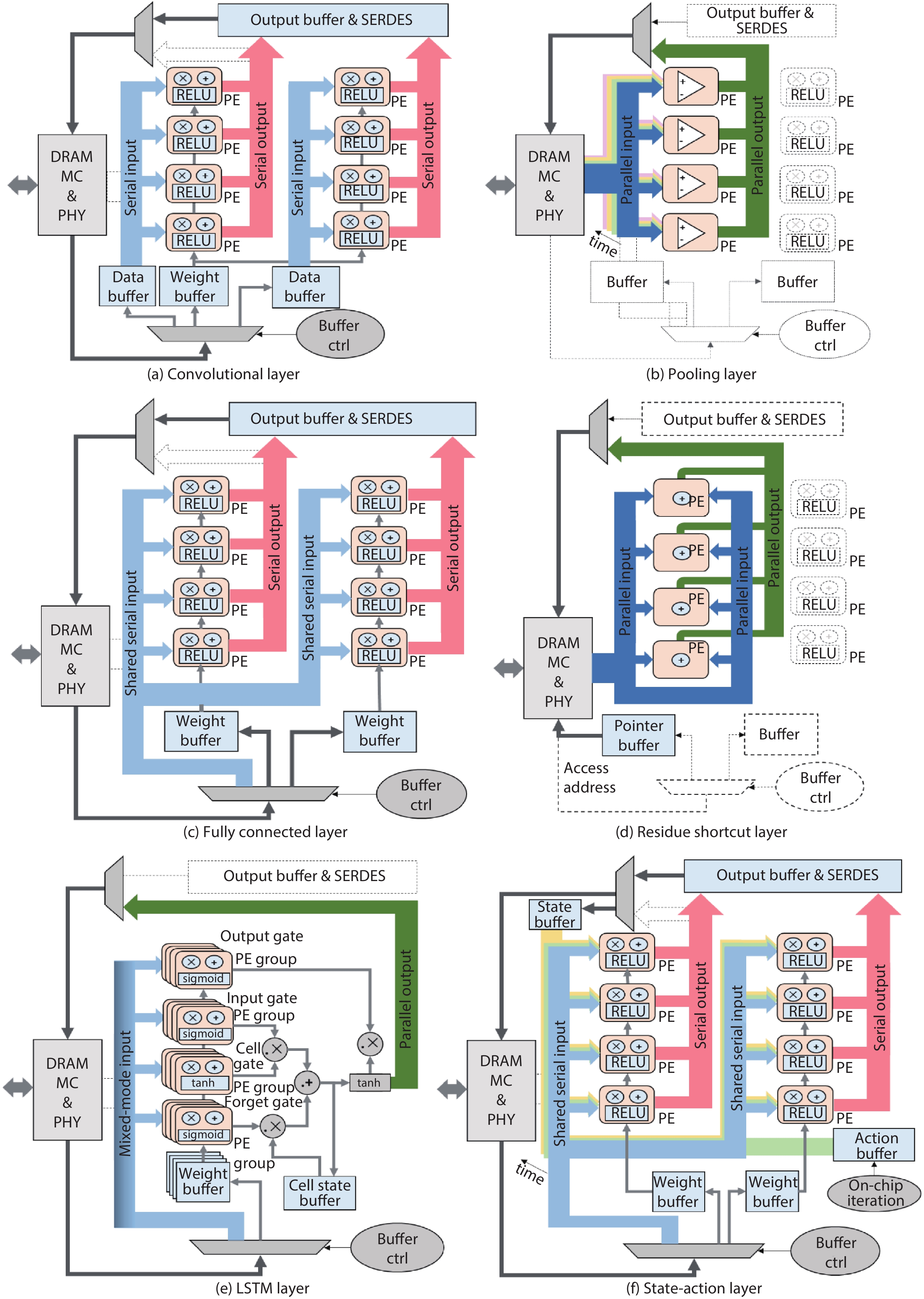
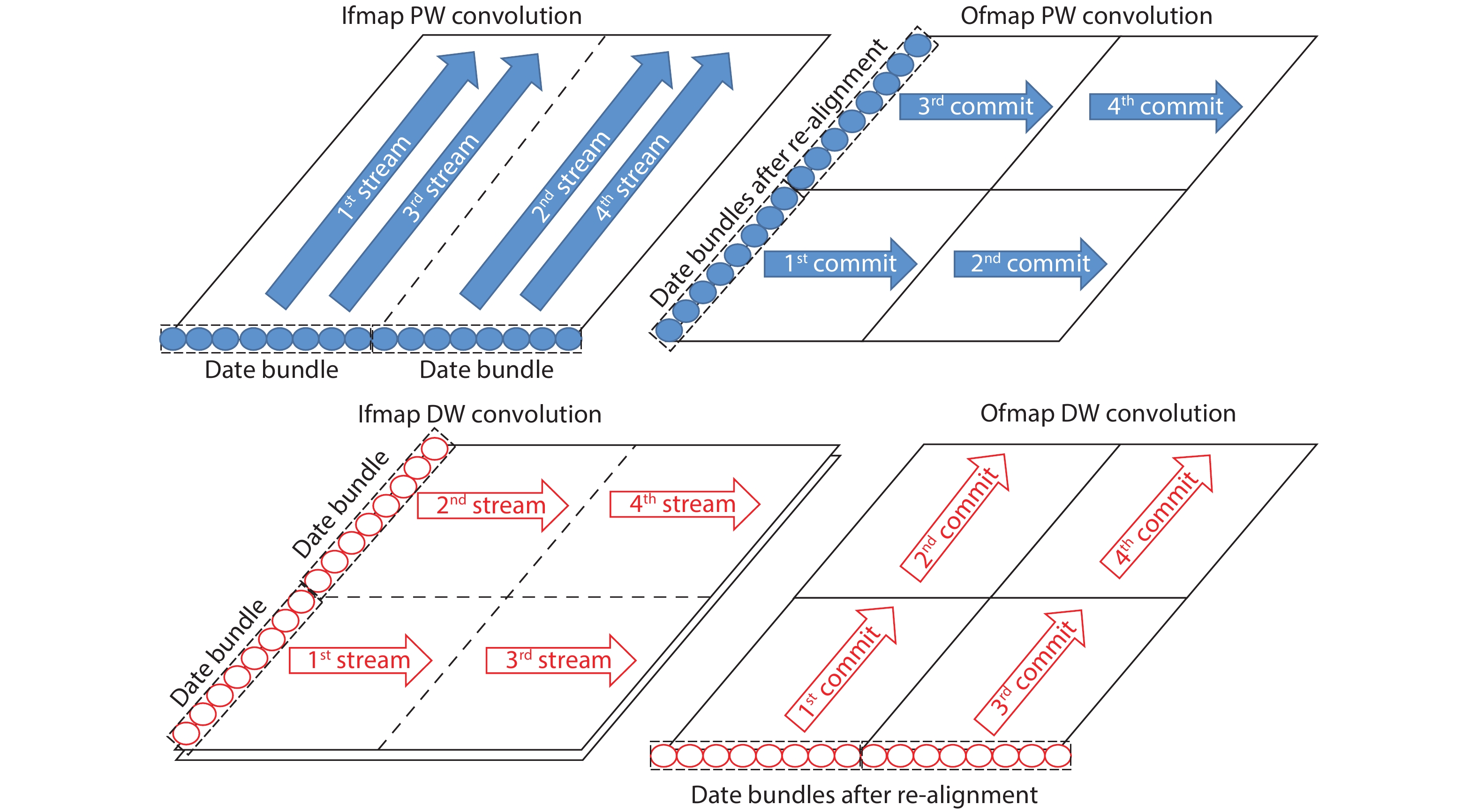
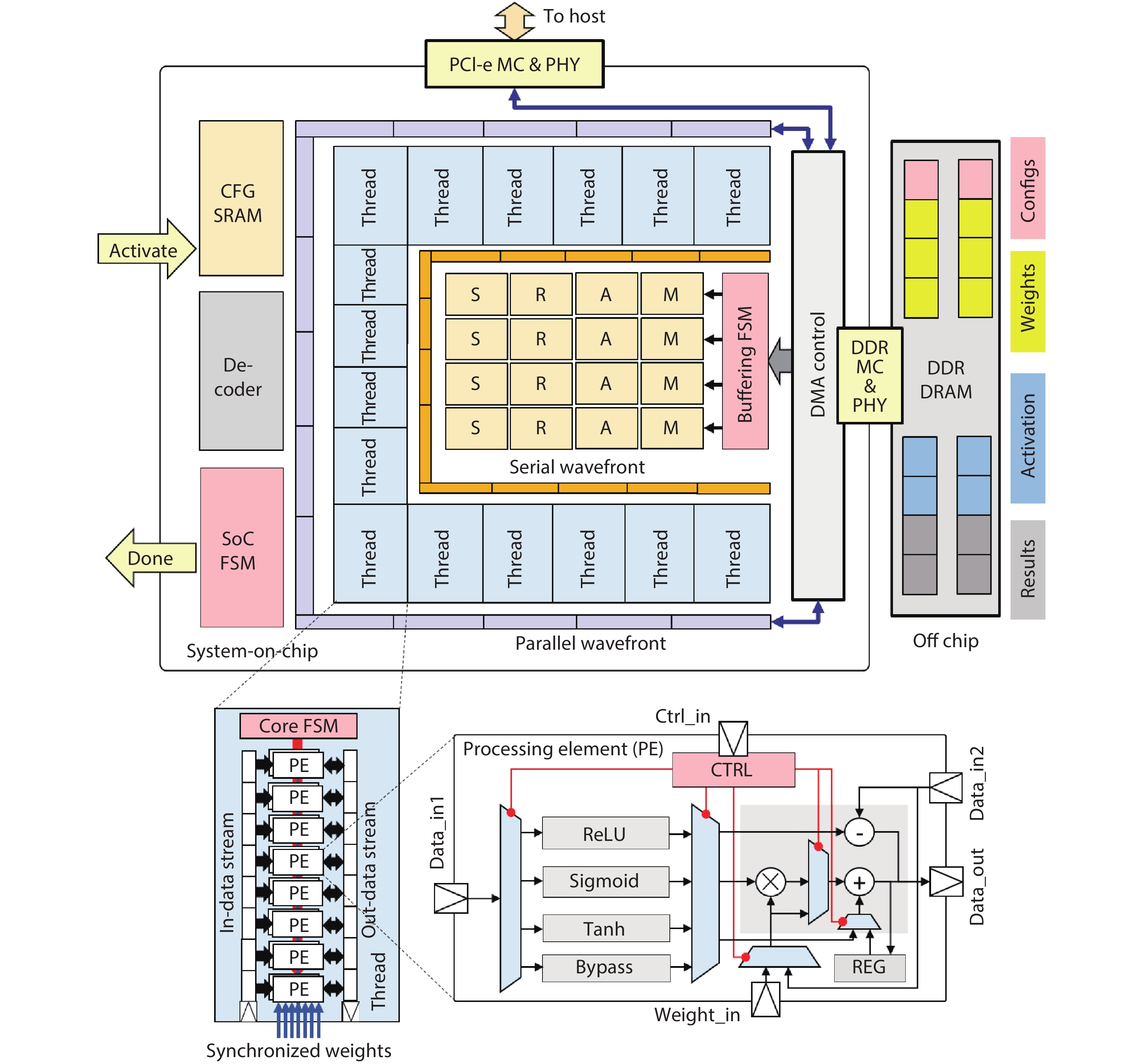


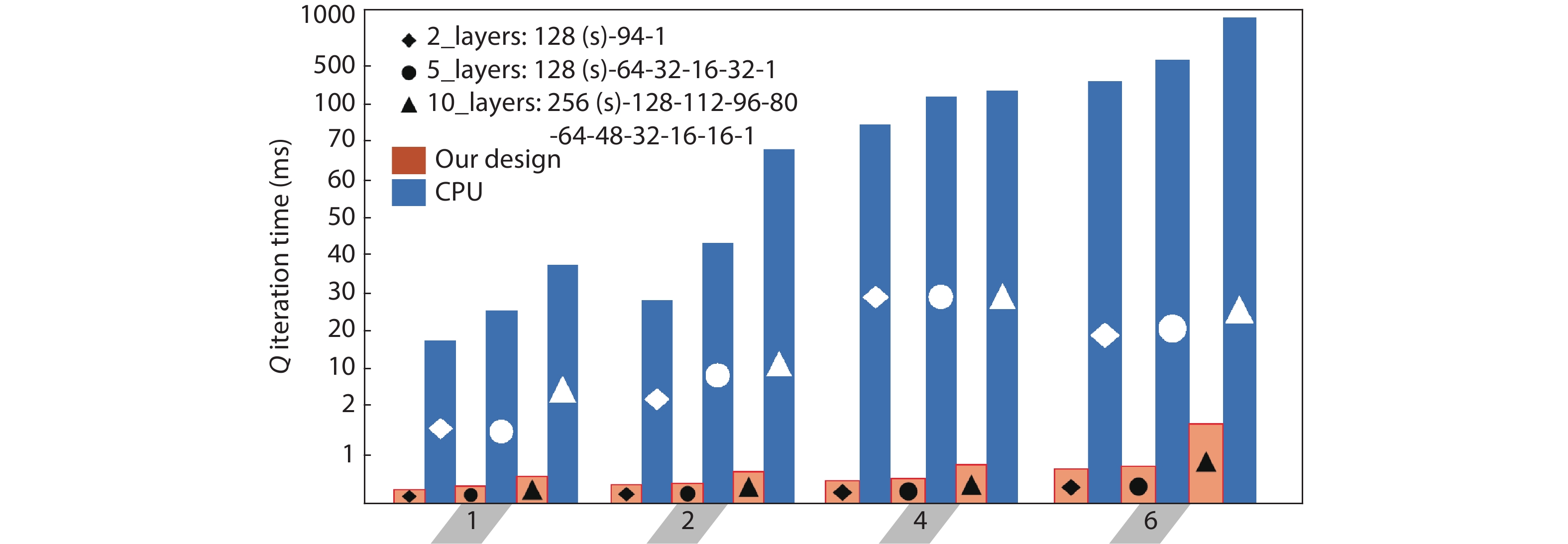



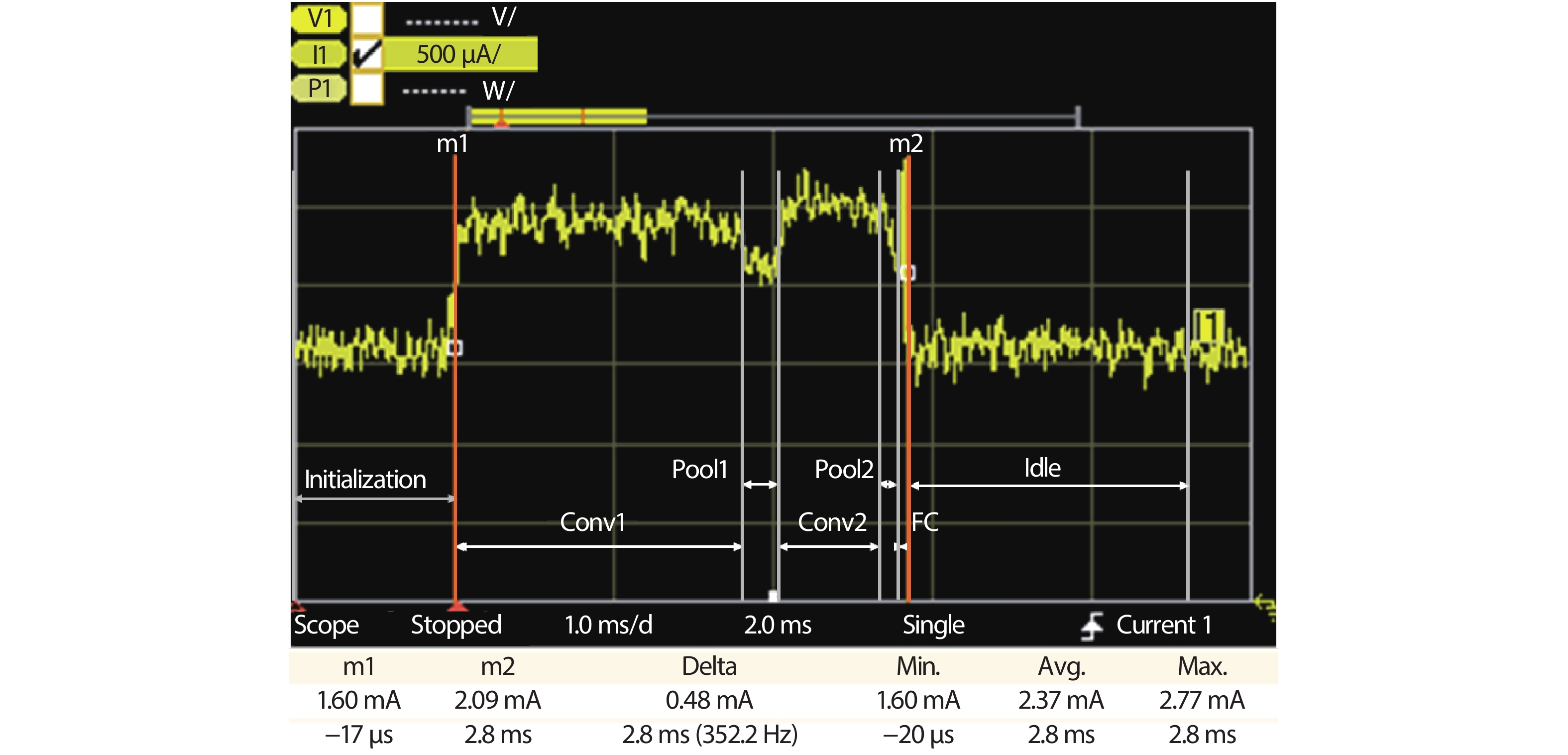
Table 1. Operation characteristics among multiple standard neural network kernels.
| NN Layer | Convolution | Pooling | FC | LSTM | State-action | Shortcut |
| Operands | Sparse matrix | Vector | Dense matrix | Dense matrix | Dense matrix | Vector |
| Operators | Sum of product (SoP) | Max, min, mean | SoP | SoP vector multiply vector sum | SoP | Vector sum |
| Nonlinear functions | ReLU sigmoid | None | ReLU sigmoid | Sigmoid tangent | ReLU sigmoid | None |
| Dataflow property | Serial in/out thread-level parallelism | Parallel in/out | Serial in/out thread-level parallelism | Serial in/out shared among gates | Serial in/out action nodes iteration | Parallel in/out |
| Buffering property | Activation dominant | Activation dominant | Weight dominant | Weight, states | Weight, states, actions | Activation pointer |
 DownLoad: CSV
DownLoad: CSV
Table 2. Number of operations of standard, DW and PW convolution layers.
| Layer | Filter size | Input size | MAC amounts |
| Standard conv | |||
| Conv DW | |||
| Conv PW |
DownLoad: CSV
Table 3. Benchmark of performance for MobileNet with proposed architecture[25].
| Layer type | Input size | #. MACs | Multi-threaded streaming architecture @ 100 MHz | Single-threaded latency (ms)[24] | ||||
| Max BW utilization | Max PE utilization | #. stream | ns / stream | Latency (ms) | ||||
| Conv0 Std. | 224 × 224 × 3 | 10.84M | 3% | 6.70% | 25088 | 3340 | 83.8 | 83.8 |
| Conv1 DW | 112 × 112 × 32 | 3.61M | 10% | 6.70% | 25088 | 2080 | 17.4 | 380.5 |
| Conv1 PW | 112 × 112 × 32 | 25.69M | 100% | 100.00% | 3136 | 1835 | 5.8 | 92.1 |
| Conv2 DW | 112 × 112 × 64 | 1.81M | 10% | 6.70% | 12544 | 2080 | 8.7 | 190.2 |
| Conv2 PW | 56 × 56 × 64 | 25.69M | 100% | 100.00% | 1568 | 3520 | 5.5 | 88.3 |
| Conv3 DW | 56 × 56 × 128 | 3.61M | 10% | 6.70% | 25088 | 2080 | 17.4 | 380.5 |
| Conv3 PW | 56 × 56 × 128 | 51.38M | 100% | 100.00% | 1568 | 6890 | 10.8 | 172.9 |
| Conv4 DW | 56 × 56 × 128 | 0.90M | 10% | 6.70% | 6272 | 2080 | 4.3 | 95.1 |
| Conv4 PW | 28 × 28 × 128 | 25.69M | 100% | 100.00% | 784 | 6890 | 5.4 | 86.4 |
| Conv5 DW | 28 × 28 × 256 | 1.81M | 10% | 6.70% | 12544 | 2080 | 8.7 | 190.2 |
| Conv5 PW | 28 × 28 × 256 | 51.38M | 100% | 100.00% | 784 | 13630 | 10.7 | 171 |
| Conv6 DW | 28 × 28 × 256 | 0.45M | 10% | 6.70% | 3136 | 2080 | 2.2 | 47.6 |
| Conv6 PW | 14 × 14 × 256 | 25.69M | 100% | 100.00% | 416 | 13630 | 5.7 | 90.7 |
| Conv7-11DW | 14 × 14 × 512 | 0.90M | 10% | 6.70% | 6272 | 2080 | 4.3 | 95.1 |
| Conv7-11PW | 14 × 14 × 512 | 51.38M | 100% | 100.00% | 416 | 27110 | 11.3 | 180.4 |
| Conv12 DW | 14 × 14 × 512 | 0.23M | 10% | 6.70% | 1568 | 2080 | 1.1 | 23.8 |
| Conv12 PW | 7 × 7 × 512 | 25.69M | 100% | 100.00% | 256 | 27110 | 6.9 | 111 |
| Conv13 DW | 7 × 7 × 1024 | 0.45M | 10% | 6.70% | 3136 | 2080 | 2.2 | 47.6 |
| Conv13 PW | 7 × 7 × 1024 | 51.38M | 100% | 100.00% | 256 | 54070 | 13.8 | 221.5 |
| Avg Pool | 7 × 7 × 1024 | 0.05M | 10% | 6.70% | 64 | 1767 | 0.1 | 0.1 |
| FC | 1 × 1 × 1024 | 1.02M | 55% | 6.70% | 63 | 90218 | 5.7 | 5.7 |
| Total | — | 569M | — | — | — | — | 294.3 | 3856.5 |
DownLoad: CSV
Table 4. Benchmark of performance for LSTM networks among three processing architectures.
| Network layer specification | 1st LSTM layer | 2nd LSTM layer (if need) | 1st FC layer (if need) | 2nd FC layer |
| In nodes: 3, Out nodes: 12, Recurrent nodes: 48 | In nodes: 12, Out nodes: 12, Recurrent nodes: 48 | In nodes: 12, Out nodes: 12 | In nodes: 12, Out nodes: 5 | |
| Network | Performance (ms/sample) | Average power consumption | ||
| 1 LSTM + 1 FC | 2 LSTM + 1 FC | 2 LSTM + 2 FC | ||
| CPU Intel i7-8700 @3.20 GHz | 11.981 | 22.362 | 23.962 | 60–70 W |
| CPU Intel i7 w. GPU NVIDIA GTX 1050 | 2.87 | 4.94 | 5.74 | 50–70 W |
| Proposed design with 16 PEs @ 100 MHz * | 1.033 | 1.157 | 1.957 | 30–50 mW |
| * Simulation result, not account for data transferring between disk storage and DRAM. | ||||
DownLoad: CSV
Table 5. Runtime power consumption in mW for different phases and frequencies.
| Frequency (MHz) | Initialize | Conv1 | Pool1 | Conv2 | Pool2 | FC | Idle | Avg. (conv1-fc) |
| 30 | 1.92 | 2.84 | 2.58 | 3.04 | 2.71 | 3.32 | 1.92 | 2.62 |
| 60 | 3.32 | 5.29 | 4.76 | 5.47 | 5.09 | 5.74 | 3.32 | 4.71 |
| 100 | 5.19 | 8.56 | 7.67 | 8.71 | 8.26 | 8.97 | 5.19 | 7.51 |
DownLoad: CSV
Table 6. Comparison of physical properties with state-of-the-art designs.
| Parameter | Eyeriss[28] | ENVISION[29] | Thinker[30] | This work | This work |
| Technology (nm) | 65 | 28 | 65 | 65 | 65 |
| Core area (mm2) | 12.25 | 1.87 | 19.36 | 3.24 | 3.24 |
| Bit precision (b) | 16 | 4/8/16 | 8/16 | 8 | 8 |
| Num. of MACs | 168 | 512 | 1024 | 16 | 256 |
| Core frequency (MHz) | 200 | 200 | 200 | 100 | 100 |
| Performance (GOPS) | 67.6 | 76 | 368.4 | 3.2 | 51.2 |
| Power (mW) | 278 | 44 | 290 | 7.51 (measured) | 55.4 (estimated) |
| Energy efficiency | 166.2 GOPS/W | 1.73 TOPS/W | 1.27 TOPS/W | 426 GOPS/W | 0.92 TOPS/W |
DownLoad: CSV
| [1] |
Chen Y, Krishna T, Emer J, et al. Eyeriss: An energy-efficient reconfigurable accelerator for deep convolutional neural networks. IEEE J Solid-State Circuits, 2017, 52, 127 doi: 10.1109/JSSC.2016.2616357
|
| [2] |
Jouppi N, Young C, Patil N, et al. In-datacenter performance analysis of a tensor processing unit. ACM/IEEE International Symposium on Computer Architecture, 2017, 1
|
| [3] |
Chen Y, Tao L, Liu S, et al. DaDianNao: A machine-learning supercomputer. ACM/IEEE International Symposium on Microarchitecture, 2015, 609
|
| [4] |
Cong J, Xiao B. Minimizing computation in convolutional neural networks. Artificial Neural Networks and Machine Learning, 2014, 281
|
| [5] |
Yin S, Ouyang P, Tang S, et al. A high energy efficient reconfigurable hybrid neural network processor for deep learning applications. IEEE J Solid-State Circuits, 2017, 53, 968 doi: 10.1109/JSSC.2017.2778281
|
| [6] |
Russakovsky O, Deng J, Su H, et al. ImageNet large scale visual recognition challenge. Int J Comput Vision, 2015, 115, 211 doi: 10.1007/s11263-015-0816-y
|
| [7] |
Iandola F, Han S, Moskewicz M, et al. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and < 0.5 MB model size. arXiv: 1602.07360, 2016
|
| [8] |
Howard A, Zhu M, Chen B, et al. MobileNets: Efficient convolutional neural networks for mobile vision applications. arXiv: 1704.04861, 2017
|
| [9] |
Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014,
|
| [10] |
Yang C, Wang Y, Wang X, et al. A reconfigurable accelerator based on fast winograd algorithm for convolutional neural network in internet of things. IEEE International Conference on Solid-State and Integrated Circuit Technology, 2018, 1
|
| [11] |
Vasilache N, Johnson J, Mathieu M, et al. Fast convolutional nets with fbfft: A GPU performance evaluation. arXiv: 1412.7580, 2014
|
| [12] |
Guo K, Zeng S, Yu J, et al. A survey of FPGA-based neural network accelerator. arXiv: 1712.08934, 2017
|
| [13] |
Mnih V, Kavukcuoglu K, Silver D, et al. Playing atari with deep reinforcement learning. arXiv: 1312.5602, 2013
|
| [14] |
Mnih V, Kavukcuoglu K, Silver D, et al. Human-level control through deep reinforcement learning. Nature, 2015, 518, 529 doi: 10.1038/nature14236
|
| [15] |
Silver D, Huang A, Maddison C, et al. Mastering the game of Go with deep neural networks and tree search. Nature, 2016, 529, 484 doi: 10.1038/nature16961
|
| [16] |
Silver D, Schrittwieser J, Simonyan K, et al. Mastering the game of Go without human knowledge. Nature, 2017, 550, 354 doi: 10.1038/nature24270
|
| [17] |
Chen Y, Emer J, Sze V. Eyeriss: A spatial architecture for energy-efficient dataflow for convolutional neural networks. ACM/IEEE International Symposium on Computer Architecture, 2016, 44, 367
|
| [18] |
Gers F, Schmidhuber J, Cummins F. Learning to forget: Continual prediction with LSTM. 9th International Conference on Artificial Neural Networks, 1999, 850 doi: 10.1049/cp:19991218
|
| [19] |
Basterretxea K, Tarela J, Del C. Approximation of sigmoid function and the derivative for hardware implementation of artificial neurons. IEE Proc Circuits, Devices Syst, 2004, 151, 18
|
| [20] |
Sutton R, Barto A. Reinforcement learning: An introduction. MIT Press, 2018
|
| [21] |
Gulli A, Sujit P. Deep learning with Keras. Packt Publishing Ltd, 2017
|
| [22] |
Li S, Ouyang N, Wang Z. Accelerator design for convolutional neural network with vertical data streaming. IEEE Asia Pacific Conference on Circuits and Systems, 2018, 544
|
| [23] |
Guo Y. Fixed point quantization of deep convolutional networks. International Conference on Machine Learning, 2016, 2849
|
| [24] |
Opalkelly product manual. https://opalkelly.com/products/frontpanel
|
| [25] |
Chen W, Wang Z, Li S, et al. Accelerating compact convolutional neural networks with multi-threaded data streaming. IEEE Computer Society Annual Symposium on VLSI, 2019, 519
|
| [26] |
MitchellSpryn solving a maze with Q learning. www.mitchellspryn.com/2017/10/28/Solving-A-Maze-With-Q-Learning.html
|
| [27] |
Liang M, Chen M, Wang Z. A CGRA based neural network inference engine for deep reinforcement learning. IEEE Asia Pacific Conference on Circuits and Systems, 2018, 519
|
| [28] |
Chen Y, Krishna T, Emer J, et al. Eyeriss: An energy-efficient reconfigurable accelerator for deep convolutional neural networks. IEEE International Solid-State Circuits Conference (ISSCC), 2016, 127
|
| [29] |
Moons B, Uytterhoeven R, Dehaene W, et al. ENVISION: A 0.26-to-10 TOPS/W subword-parallel dynamic-voltage-accuracy-frequency-scalable convolutional neural network processor in 28 nm FDSOI. IEEE International Solid-State Circuits Conference (ISSCC), 2017, 246
|
| [30] |
Yin S, Ouyang P, Tang S, et al. 1.06-to-5.09 TOPS/W reconfigurable hybrid-neural-network processor for deep learning applications. Symposium on VLSI Circuits, 2017
|









Article views: 6767 Times PDF downloads: 144 Times Cited by: 0 Times
Received: 08 October 2019 Revised: 16 December 2019 Online: Uncorrected proof: 25 December 2019Accepted Manuscript: 26 December 2019Published: 11 February 2020
| Citation: |
Zheng Wang, Libing Zhou, Wenting Xie, Weiguang Chen, Jinyuan Su, Wenxuan Chen, Anhua Du, Shanliao Li, Minglan Liang, Yuejin Lin, Wei Zhao, Yanze Wu, Tianfu Sun, Wenqi Fang, Zhibin Yu. Accelerating hybrid and compact neural networks targeting perception and control domains with coarse-grained dataflow reconfiguration[J]. Journal of Semiconductors, 2020, 41(2): 022401. doi: 10.1088/1674-4926/41/2/022401
****
Z Wang, L B Zhou, W T Xie, W G Chen, J Y Su, W X Chen, A H Du, S L Li, M L Liang, Y J Lin, W Zhao, Y Z Wu, T F Sun, W Q Fang, Z B Yu, Accelerating hybrid and compact neural networks targeting perception and control domains with coarse-grained dataflow reconfiguration[J]. J. Semicond., 2020, 41(2): 022401. doi: 10.1088/1674-4926/41/2/022401.

|
| [1] |
Chen Y, Krishna T, Emer J, et al. Eyeriss: An energy-efficient reconfigurable accelerator for deep convolutional neural networks. IEEE J Solid-State Circuits, 2017, 52, 127 doi: 10.1109/JSSC.2016.2616357
|
| [2] |
Jouppi N, Young C, Patil N, et al. In-datacenter performance analysis of a tensor processing unit. ACM/IEEE International Symposium on Computer Architecture, 2017, 1
|
| [3] |
Chen Y, Tao L, Liu S, et al. DaDianNao: A machine-learning supercomputer. ACM/IEEE International Symposium on Microarchitecture, 2015, 609
|
| [4] |
Cong J, Xiao B. Minimizing computation in convolutional neural networks. Artificial Neural Networks and Machine Learning, 2014, 281
|
| [5] |
Yin S, Ouyang P, Tang S, et al. A high energy efficient reconfigurable hybrid neural network processor for deep learning applications. IEEE J Solid-State Circuits, 2017, 53, 968 doi: 10.1109/JSSC.2017.2778281
|
| [6] |
Russakovsky O, Deng J, Su H, et al. ImageNet large scale visual recognition challenge. Int J Comput Vision, 2015, 115, 211 doi: 10.1007/s11263-015-0816-y
|
| [7] |
Iandola F, Han S, Moskewicz M, et al. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and < 0.5 MB model size. arXiv: 1602.07360, 2016
|
| [8] |
Howard A, Zhu M, Chen B, et al. MobileNets: Efficient convolutional neural networks for mobile vision applications. arXiv: 1704.04861, 2017
|
| [9] |
Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014,
|
| [10] |
Yang C, Wang Y, Wang X, et al. A reconfigurable accelerator based on fast winograd algorithm for convolutional neural network in internet of things. IEEE International Conference on Solid-State and Integrated Circuit Technology, 2018, 1
|
| [11] |
Vasilache N, Johnson J, Mathieu M, et al. Fast convolutional nets with fbfft: A GPU performance evaluation. arXiv: 1412.7580, 2014
|
| [12] |
Guo K, Zeng S, Yu J, et al. A survey of FPGA-based neural network accelerator. arXiv: 1712.08934, 2017
|
| [13] |
Mnih V, Kavukcuoglu K, Silver D, et al. Playing atari with deep reinforcement learning. arXiv: 1312.5602, 2013
|
| [14] |
Mnih V, Kavukcuoglu K, Silver D, et al. Human-level control through deep reinforcement learning. Nature, 2015, 518, 529 doi: 10.1038/nature14236
|
| [15] |
Silver D, Huang A, Maddison C, et al. Mastering the game of Go with deep neural networks and tree search. Nature, 2016, 529, 484 doi: 10.1038/nature16961
|
| [16] |
Silver D, Schrittwieser J, Simonyan K, et al. Mastering the game of Go without human knowledge. Nature, 2017, 550, 354 doi: 10.1038/nature24270
|
| [17] |
Chen Y, Emer J, Sze V. Eyeriss: A spatial architecture for energy-efficient dataflow for convolutional neural networks. ACM/IEEE International Symposium on Computer Architecture, 2016, 44, 367
|
| [18] |
Gers F, Schmidhuber J, Cummins F. Learning to forget: Continual prediction with LSTM. 9th International Conference on Artificial Neural Networks, 1999, 850 doi: 10.1049/cp:19991218
|
| [19] |
Basterretxea K, Tarela J, Del C. Approximation of sigmoid function and the derivative for hardware implementation of artificial neurons. IEE Proc Circuits, Devices Syst, 2004, 151, 18
|
| [20] |
Sutton R, Barto A. Reinforcement learning: An introduction. MIT Press, 2018
|
| [21] |
Gulli A, Sujit P. Deep learning with Keras. Packt Publishing Ltd, 2017
|
| [22] |
Li S, Ouyang N, Wang Z. Accelerator design for convolutional neural network with vertical data streaming. IEEE Asia Pacific Conference on Circuits and Systems, 2018, 544
|
| [23] |
Guo Y. Fixed point quantization of deep convolutional networks. International Conference on Machine Learning, 2016, 2849
|
| [24] |
Opalkelly product manual. https://opalkelly.com/products/frontpanel
|
| [25] |
Chen W, Wang Z, Li S, et al. Accelerating compact convolutional neural networks with multi-threaded data streaming. IEEE Computer Society Annual Symposium on VLSI, 2019, 519
|
| [26] |
MitchellSpryn solving a maze with Q learning. www.mitchellspryn.com/2017/10/28/Solving-A-Maze-With-Q-Learning.html
|
| [27] |
Liang M, Chen M, Wang Z. A CGRA based neural network inference engine for deep reinforcement learning. IEEE Asia Pacific Conference on Circuits and Systems, 2018, 519
|
| [28] |
Chen Y, Krishna T, Emer J, et al. Eyeriss: An energy-efficient reconfigurable accelerator for deep convolutional neural networks. IEEE International Solid-State Circuits Conference (ISSCC), 2016, 127
|
| [29] |
Moons B, Uytterhoeven R, Dehaene W, et al. ENVISION: A 0.26-to-10 TOPS/W subword-parallel dynamic-voltage-accuracy-frequency-scalable convolutional neural network processor in 28 nm FDSOI. IEEE International Solid-State Circuits Conference (ISSCC), 2017, 246
|
| [30] |
Yin S, Ouyang P, Tang S, et al. 1.06-to-5.09 TOPS/W reconfigurable hybrid-neural-network processor for deep learning applications. Symposium on VLSI Circuits, 2017
|
 WeChat ID
WeChat ID
Journal of Semiconductors © 2017 All Rights Reserved 京ICP備05085259號(hào)-2