



Fig. 1.
(Color online) Simplified architecture of (a) baseline DSP and (b) enhanced DSP.
REVIEWS
Zhengjie Li, Yufan Zhang, Jian Wang and Jinmei Lai
Corresponding author: Jinmei Lai, Email: jmlai@fudan.edu.cn
Abstract: FPGA is an appealing platform to accelerate DNN. We survey a range of FPGA chip designs for AI. For DSP module, one type of design is to support low-precision operation, such as 9-bit or 4-bit multiplication. The other type of design of DSP is to support floating point multiply-accumulates (MACs), which guarantee high-accuracy of DNN. For ALM (adaptive logic module) module, one type of design is to support low-precision MACs, three modifications of ALM includes extra carry chain, or 4-bit adder, or shadow multipliers which increase the density of on-chip MAC operation. The other enhancement of ALM or CLB (configurable logic block) is to support BNN (binarized neural network) which is ultra-reduced precision version of DNN. For memory modules which can store weights and activations of DNN, three types of memory are proposed which are embedded memory, in-package HBM (high bandwidth memory) and off-chip memory interfaces, such as DDR4/5. Other designs are new architecture and specialized AI engine. Xilinx ACAP in 7 nm is the first industry adaptive compute acceleration platform. Its AI engine can provide up to 8X silicon compute density. Intel AgileX in 10 nm works coherently with Intel own CPU, which increase computation performance, reduced overhead and latency.
| [1] |
Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks. Neural Information Processing Systems (NIPS), 2012, 1097
|
| [2] |
Liang S, Yin S, Liu L, et al. FP-BNN: Binarized neural network on FPGA. Neurocomputing, 2017, 275, 1072
|
| [3] |
Freund K. Machine learning application landscape. https://www.xilinx.com/support/documentation/backgrounders/Machine-Learning-Application-Landscape.pdf. 2017
|
| [4] |
Zhang C, Li P, Sun G, et al. Optimizing FPGA-based accelerator design for deep convolutional neural networks. The 2015 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2015, 161
|
| [5] |
Qiu J, Wang J, Yao S, et al. Going deeper with embedded FPGA platform for convolutional neural network. The 2016 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2016, 26
|
| [6] |
Yin S, Ouyang P, Tang S, et al. A high energy efficient reconfigurable hybrid neural network processor for deep learning applications. IEEE J Solid-State Circuits, 2018, 53(4), 968 doi: 10.1109/JSSC.2017.2778281
|
| [7] |
Han S, Mao H, Dally W J. Deep compression: compressing deep neural networks with pruning, trained quantization and huffman coding. ICLR, 2016
|
| [8] |
Gysel P, Motamedi M, Ghiasi S. Hardware-oriented approximation of convolutional neural networks. ICLR, 2016
|
| [9] |
Han S, Liu X, Mao H, et al. EIE: efficient inference engine on compressed deep neural network. International Symposium on Computer Architecture (ISCA), 2016, 243
|
| [10] |
Zhou A, Yao A, Guo Y, et al. Incremental network quantization: towards lossless CNNs with low-precision weights. ICLR, 2017
|
| [11] |
Mishra A, Nurvitadhi E, Cook J J, et al. WRPN: wide reduced-precision networks. arXiv: 1709.01134, 2017
|
| [12] |
Hubara I, Courbariaux M, Soudry D. Binarized neural networks. Neural Information Processing Systems (NIPS), 2016, 1
|
| [13] |
Umuroglu Y, Fraser N J, Gambardella G, et al. FINN: A framework for fast, scalable binarized neural network inference. International Symposium on Field-Programmable Gate Arrays, 2017, 65
|
| [14] |
Boutros A, Yazdanshenas S, Betz V. Embracing diversity: Enhanced DSP blocks for low precision deep learning on FPGAs. 28th International Conference on Field-Programmable Logic and Applications, 2018, 35
|
| [15] |
Won M S. Intel? AgilexTM FPGA architecture. https://www.intel.com/content/www/us/en/products/programmable/fpga/agilex.html. Intel White Paper
|
| [16] |
Versal: The first adaptive compute acceleration platform (ACAP). https://www.xilinx.com/support/documentation/white_papers/wp505-versal-acap.pdf. Xilinx White Paper. Version: v1.0, October 2, 2018
|
| [17] |
Boutros A, Eldafrawy M, Yazdanshenas S, et al. Math doesn’t have to be hard: logic block architectures to enhance low-precision multiply-accumulate on FPGAs. The 2019 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2019, 94
|
| [18] |
Kim J H, Lee J, Anderson J H. FPGA architecture enhancements for efficient BNN implementation. International Conference on Field-Programmable Technology (ICFPT), 2018, 217
|
| [19] |
Versal architecture and product data sheet: overview. https://www.xilinx.com/support/documentation/data_sheets/ds950-versal-overview.pdf. DS950. Version: v1.2, July 3, 2019
|
| [20] |
Xilinx AI engines and their applications. https://www.xilinx.com/support/documentation/white_papers/wp506-ai-engine.pdf. Xilinx White Paper. Version: v1.0.2, October 3, 2018
|
| [21] |
Intel Arria 10 core fabric and general purpose I/Os handbook. https://www.intel.com/content/dam/www/programmable/us/en/pdfs/literature/hb/arria-10/a10_handbook.pdf. Version: 2018.06.24
|
| [22] |
Intel? Stratix? 10 variable precision DSP blocks user guide. https://www.intel.com/content/dam/www/programmable/us/en/pdfs/literature/hb/stratix-10/ug-s10-dsp.pdf. Version: 2018.09.24
|
| [23] |
Yazdanshenas S, Betz V. Automatic circuit design and modelling for heterogeneous FPGAs. International Conference on Field-Programmable Technology (ICFPT), 2017, 9
|
| [24] |
Yazdanshenas S, Betz V. COFFE 2: Automatic modelling and optimization of complex and heterogeneous FPGA architectures. ACM Trans Reconfig Technol Syst, 2018, 12(1), 3 doi: 10.1145/3301298
|
| [25] |
Versal ACAP AI core series product selection guide. https://www.xilinx.com/support/documentation/selection-guides/versal-ai-core-product-selection-guide.pdf. XMP452. Version: v1.0.1, 2018
|
| [26] |
UltraScale architecture DSP slice user guide. https://www.xilinx.com/support/documentation/user_guides/ug579-ultrascale-dsp.pdf. UG579. Version: v1.9, September 20, 2019
|
| [27] |
Langhammer M, Pasca B. Floating-point DSP block architecture for FPGAs. The 2015 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2015, 117
|
| [28] |
Intel? AgilexTM FPGA advanced information brief. https://www.intel.com/content/dam/www/programmable/us/en/pdfs/literature/hb/agilex/ag-overview.pdf. AG-OVERVIEW Version: 2019.07.02
|

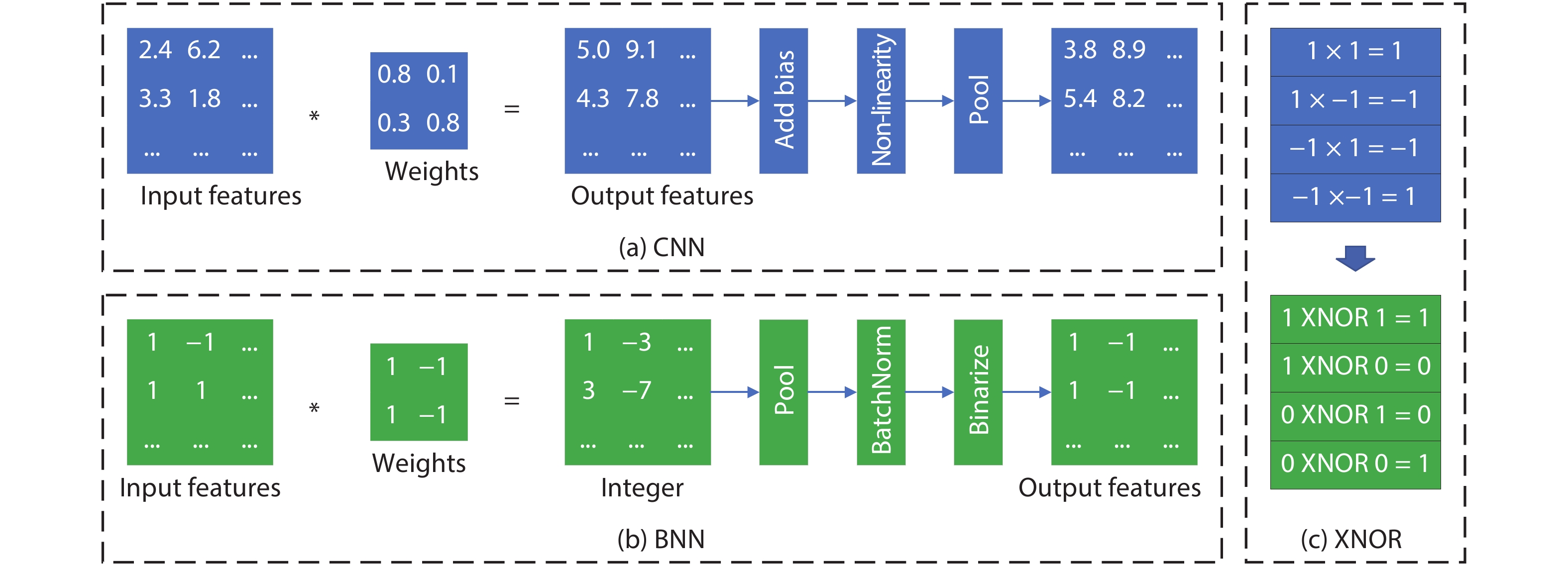
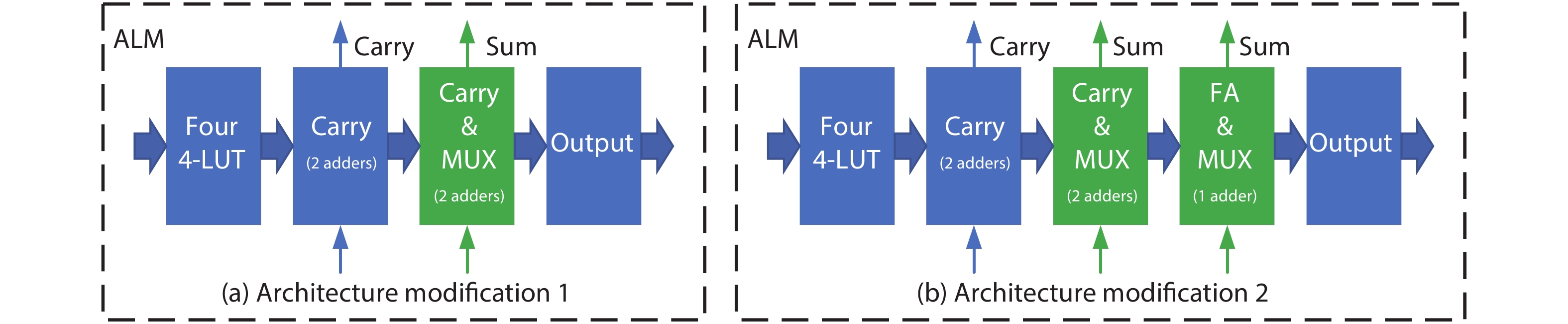
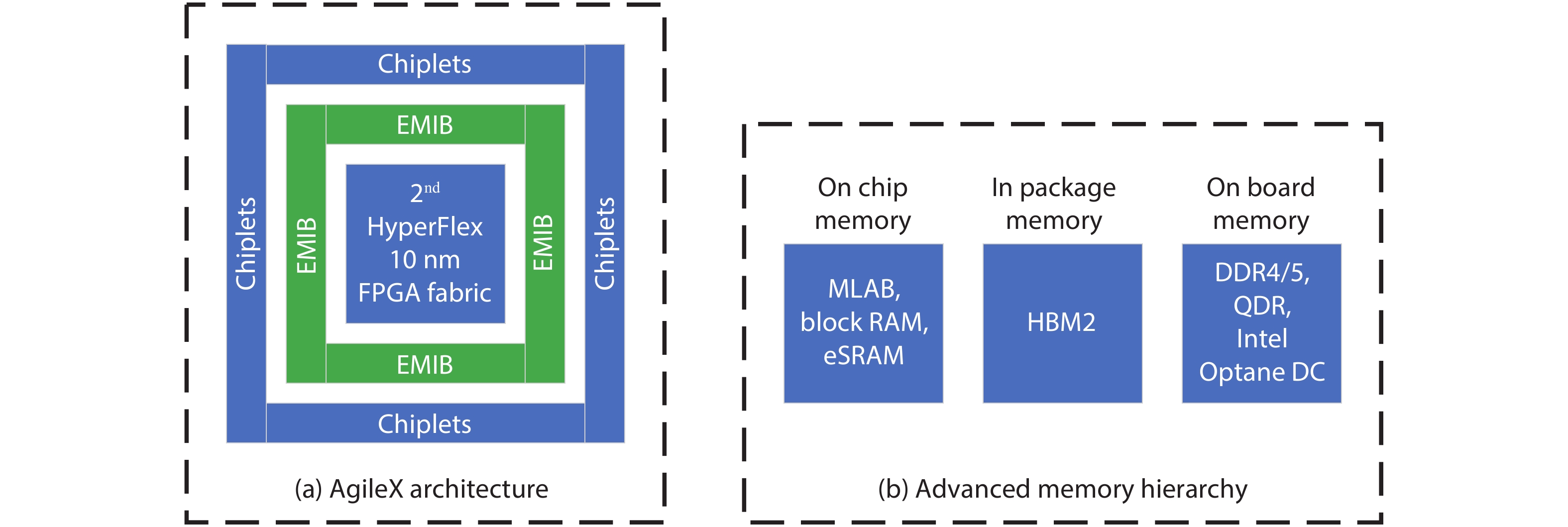
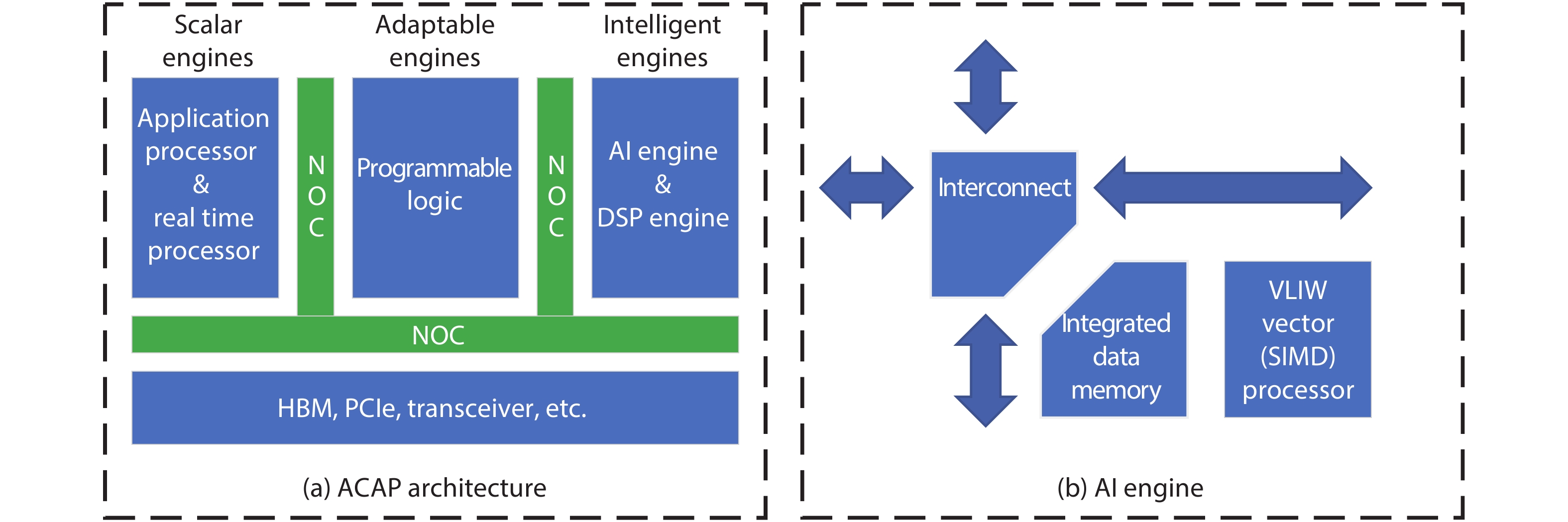
Table 1. Summary of all enhancements of FPGA for AI era.
| No. | Inventor | Module | Goal | Enhancement | Advantage |
| 1 | A Boutros et al.[14] | DSP | Low-precision computation | DSP block to support 9-bit and 4-bit multiplication | Pack 2 × as many 9-bit and 4 × as many 4-bit multiplications compared to the baseline Arria-10-like DSP |
| 2 | Intel[15] | DSP | Low-precision computation | AgileX supports INT8 computation | Provide 2 × the number of 9 × 9 multipliers and doubles the amount of INT8 operations compared to the prior generation. |
| 3 | Intel[15] | DSP | High-accuracy computation | AgileX supports FP32, FP16 and BFLOAT16 | Provide up to 40 TFLOPs FP16 or BF16, or up to 20 TFLOPs FP32 DSP performance |
| 4 | Xilinx[16] | DSP | Low-precision computation | DSP Engine supports INT8 computation | VC1902 of AI Core Series provides INT8 peak performance up to 13.6 TOP/s[25] |
| 5 | Xilinx[16] | DSP | High-accuracy computation | DSP Engine supports FP32 and FP16 | VC1902 of AI Core Series provides FP32 peak performance up to 3.2 TFLOP/s[25] |
| 6 | A Boutros et al.[17] | ALM | Low-precision computation | ALM with extra carry chain, or more adders, or shadow multipliers | Extra carry chain provides a 1.5 × increase in MAC density; 4-bit adder and 9-bit shadow multiplier provides a 6.1 × increase in MAC density |
| 7 | J H Kim et al. [18] | ALM/CLB | Support BNN | Extra carry chain which propagates sum; additional FA | The first change reduces ALM/LUT usage by 23%–44%; the second change reduces ALM/LUT usage by 39%–60%[18]. |
| 8 | Intel[15] | Memory | Support more memory resources | Embedded memory, in-package HBM, off-chip memory interfaces | On-chip memory includes MLABs (640b), block RAM (M20K), and eSRAM (18 MB); in-package memory includes HBM2E; on-board memory includes DDR4/5, QDR/ RLDRAM, Intel Optane DC Persistent Memory |
| 10 | Xilinx[16] | Memory | Support more memory resources | Embedded memory, off-chip memory interfaces | Distributed-RAM(64-bit per CLB), block RAM (36 KB), UltraRAM (288 KB), Accelerator RAM; DDR4/LPDDR4 |
| 11 | Xilinx[20] | AI Engine | Artificial intelligence | An array of VLIW SIMD high-performance processors[20] | Deliver up to 8X silicon compute density at 50% the power consumption of traditional programmable logic solutions[20] |
| 12 | Intel[15] | Platform | For data-centric world | 10-nm Agilex; innovative chipletarchitecture[28] | Deliver up to 40% higher core performance, or up to 40% lower power over previous generation FPGAs[28] |
| 13 | Xilinx[16] | Platform | Adaptive compute acceleration platforms | Intelligent engines (AI and DSP), adaptable engines, andscalar engines | Achieve performance improvements of up to 20X over today's fastest FPGA implementations and over 100X over today's fastest CPU implementations[19] |
 DownLoad: CSV
DownLoad: CSV
| [1] |
Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks. Neural Information Processing Systems (NIPS), 2012, 1097
|
| [2] |
Liang S, Yin S, Liu L, et al. FP-BNN: Binarized neural network on FPGA. Neurocomputing, 2017, 275, 1072
|
| [3] |
Freund K. Machine learning application landscape. https://www.xilinx.com/support/documentation/backgrounders/Machine-Learning-Application-Landscape.pdf. 2017
|
| [4] |
Zhang C, Li P, Sun G, et al. Optimizing FPGA-based accelerator design for deep convolutional neural networks. The 2015 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2015, 161
|
| [5] |
Qiu J, Wang J, Yao S, et al. Going deeper with embedded FPGA platform for convolutional neural network. The 2016 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2016, 26
|
| [6] |
Yin S, Ouyang P, Tang S, et al. A high energy efficient reconfigurable hybrid neural network processor for deep learning applications. IEEE J Solid-State Circuits, 2018, 53(4), 968 doi: 10.1109/JSSC.2017.2778281
|
| [7] |
Han S, Mao H, Dally W J. Deep compression: compressing deep neural networks with pruning, trained quantization and huffman coding. ICLR, 2016
|
| [8] |
Gysel P, Motamedi M, Ghiasi S. Hardware-oriented approximation of convolutional neural networks. ICLR, 2016
|
| [9] |
Han S, Liu X, Mao H, et al. EIE: efficient inference engine on compressed deep neural network. International Symposium on Computer Architecture (ISCA), 2016, 243
|
| [10] |
Zhou A, Yao A, Guo Y, et al. Incremental network quantization: towards lossless CNNs with low-precision weights. ICLR, 2017
|
| [11] |
Mishra A, Nurvitadhi E, Cook J J, et al. WRPN: wide reduced-precision networks. arXiv: 1709.01134, 2017
|
| [12] |
Hubara I, Courbariaux M, Soudry D. Binarized neural networks. Neural Information Processing Systems (NIPS), 2016, 1
|
| [13] |
Umuroglu Y, Fraser N J, Gambardella G, et al. FINN: A framework for fast, scalable binarized neural network inference. International Symposium on Field-Programmable Gate Arrays, 2017, 65
|
| [14] |
Boutros A, Yazdanshenas S, Betz V. Embracing diversity: Enhanced DSP blocks for low precision deep learning on FPGAs. 28th International Conference on Field-Programmable Logic and Applications, 2018, 35
|
| [15] |
Won M S. Intel? AgilexTM FPGA architecture. https://www.intel.com/content/www/us/en/products/programmable/fpga/agilex.html. Intel White Paper
|
| [16] |
Versal: The first adaptive compute acceleration platform (ACAP). https://www.xilinx.com/support/documentation/white_papers/wp505-versal-acap.pdf. Xilinx White Paper. Version: v1.0, October 2, 2018
|
| [17] |
Boutros A, Eldafrawy M, Yazdanshenas S, et al. Math doesn’t have to be hard: logic block architectures to enhance low-precision multiply-accumulate on FPGAs. The 2019 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2019, 94
|
| [18] |
Kim J H, Lee J, Anderson J H. FPGA architecture enhancements for efficient BNN implementation. International Conference on Field-Programmable Technology (ICFPT), 2018, 217
|
| [19] |
Versal architecture and product data sheet: overview. https://www.xilinx.com/support/documentation/data_sheets/ds950-versal-overview.pdf. DS950. Version: v1.2, July 3, 2019
|
| [20] |
Xilinx AI engines and their applications. https://www.xilinx.com/support/documentation/white_papers/wp506-ai-engine.pdf. Xilinx White Paper. Version: v1.0.2, October 3, 2018
|
| [21] |
Intel Arria 10 core fabric and general purpose I/Os handbook. https://www.intel.com/content/dam/www/programmable/us/en/pdfs/literature/hb/arria-10/a10_handbook.pdf. Version: 2018.06.24
|
| [22] |
Intel? Stratix? 10 variable precision DSP blocks user guide. https://www.intel.com/content/dam/www/programmable/us/en/pdfs/literature/hb/stratix-10/ug-s10-dsp.pdf. Version: 2018.09.24
|
| [23] |
Yazdanshenas S, Betz V. Automatic circuit design and modelling for heterogeneous FPGAs. International Conference on Field-Programmable Technology (ICFPT), 2017, 9
|
| [24] |
Yazdanshenas S, Betz V. COFFE 2: Automatic modelling and optimization of complex and heterogeneous FPGA architectures. ACM Trans Reconfig Technol Syst, 2018, 12(1), 3 doi: 10.1145/3301298
|
| [25] |
Versal ACAP AI core series product selection guide. https://www.xilinx.com/support/documentation/selection-guides/versal-ai-core-product-selection-guide.pdf. XMP452. Version: v1.0.1, 2018
|
| [26] |
UltraScale architecture DSP slice user guide. https://www.xilinx.com/support/documentation/user_guides/ug579-ultrascale-dsp.pdf. UG579. Version: v1.9, September 20, 2019
|
| [27] |
Langhammer M, Pasca B. Floating-point DSP block architecture for FPGAs. The 2015 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2015, 117
|
| [28] |
Intel? AgilexTM FPGA advanced information brief. https://www.intel.com/content/dam/www/programmable/us/en/pdfs/literature/hb/agilex/ag-overview.pdf. AG-OVERVIEW Version: 2019.07.02
|









Article views: 7235 Times PDF downloads: 340 Times Cited by: 0 Times
Received: 26 September 2019 Revised: 19 October 2019 Online: Accepted Manuscript: 14 December 2019Uncorrected proof: 17 December 2019Published: 11 February 2020
| Citation: |
Zhengjie Li, Yufan Zhang, Jian Wang, Jinmei Lai. A survey of FPGA design for AI era[J]. Journal of Semiconductors, 2020, 41(2): 021402. doi: 10.1088/1674-4926/41/2/021402
****
Z J Li, Y F Zhang, J Wang, J M Lai, A survey of FPGA design for AI era[J]. J. Semicond., 2020, 41(2): 021402. doi: 10.1088/1674-4926/41/2/021402.

|
| [1] |
Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks. Neural Information Processing Systems (NIPS), 2012, 1097
|
| [2] |
Liang S, Yin S, Liu L, et al. FP-BNN: Binarized neural network on FPGA. Neurocomputing, 2017, 275, 1072
|
| [3] |
Freund K. Machine learning application landscape. https://www.xilinx.com/support/documentation/backgrounders/Machine-Learning-Application-Landscape.pdf. 2017
|
| [4] |
Zhang C, Li P, Sun G, et al. Optimizing FPGA-based accelerator design for deep convolutional neural networks. The 2015 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2015, 161
|
| [5] |
Qiu J, Wang J, Yao S, et al. Going deeper with embedded FPGA platform for convolutional neural network. The 2016 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2016, 26
|
| [6] |
Yin S, Ouyang P, Tang S, et al. A high energy efficient reconfigurable hybrid neural network processor for deep learning applications. IEEE J Solid-State Circuits, 2018, 53(4), 968 doi: 10.1109/JSSC.2017.2778281
|
| [7] |
Han S, Mao H, Dally W J. Deep compression: compressing deep neural networks with pruning, trained quantization and huffman coding. ICLR, 2016
|
| [8] |
Gysel P, Motamedi M, Ghiasi S. Hardware-oriented approximation of convolutional neural networks. ICLR, 2016
|
| [9] |
Han S, Liu X, Mao H, et al. EIE: efficient inference engine on compressed deep neural network. International Symposium on Computer Architecture (ISCA), 2016, 243
|
| [10] |
Zhou A, Yao A, Guo Y, et al. Incremental network quantization: towards lossless CNNs with low-precision weights. ICLR, 2017
|
| [11] |
Mishra A, Nurvitadhi E, Cook J J, et al. WRPN: wide reduced-precision networks. arXiv: 1709.01134, 2017
|
| [12] |
Hubara I, Courbariaux M, Soudry D. Binarized neural networks. Neural Information Processing Systems (NIPS), 2016, 1
|
| [13] |
Umuroglu Y, Fraser N J, Gambardella G, et al. FINN: A framework for fast, scalable binarized neural network inference. International Symposium on Field-Programmable Gate Arrays, 2017, 65
|
| [14] |
Boutros A, Yazdanshenas S, Betz V. Embracing diversity: Enhanced DSP blocks for low precision deep learning on FPGAs. 28th International Conference on Field-Programmable Logic and Applications, 2018, 35
|
| [15] |
Won M S. Intel? AgilexTM FPGA architecture. https://www.intel.com/content/www/us/en/products/programmable/fpga/agilex.html. Intel White Paper
|
| [16] |
Versal: The first adaptive compute acceleration platform (ACAP). https://www.xilinx.com/support/documentation/white_papers/wp505-versal-acap.pdf. Xilinx White Paper. Version: v1.0, October 2, 2018
|
| [17] |
Boutros A, Eldafrawy M, Yazdanshenas S, et al. Math doesn’t have to be hard: logic block architectures to enhance low-precision multiply-accumulate on FPGAs. The 2019 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2019, 94
|
| [18] |
Kim J H, Lee J, Anderson J H. FPGA architecture enhancements for efficient BNN implementation. International Conference on Field-Programmable Technology (ICFPT), 2018, 217
|
| [19] |
Versal architecture and product data sheet: overview. https://www.xilinx.com/support/documentation/data_sheets/ds950-versal-overview.pdf. DS950. Version: v1.2, July 3, 2019
|
| [20] |
Xilinx AI engines and their applications. https://www.xilinx.com/support/documentation/white_papers/wp506-ai-engine.pdf. Xilinx White Paper. Version: v1.0.2, October 3, 2018
|
| [21] |
Intel Arria 10 core fabric and general purpose I/Os handbook. https://www.intel.com/content/dam/www/programmable/us/en/pdfs/literature/hb/arria-10/a10_handbook.pdf. Version: 2018.06.24
|
| [22] |
Intel? Stratix? 10 variable precision DSP blocks user guide. https://www.intel.com/content/dam/www/programmable/us/en/pdfs/literature/hb/stratix-10/ug-s10-dsp.pdf. Version: 2018.09.24
|
| [23] |
Yazdanshenas S, Betz V. Automatic circuit design and modelling for heterogeneous FPGAs. International Conference on Field-Programmable Technology (ICFPT), 2017, 9
|
| [24] |
Yazdanshenas S, Betz V. COFFE 2: Automatic modelling and optimization of complex and heterogeneous FPGA architectures. ACM Trans Reconfig Technol Syst, 2018, 12(1), 3 doi: 10.1145/3301298
|
| [25] |
Versal ACAP AI core series product selection guide. https://www.xilinx.com/support/documentation/selection-guides/versal-ai-core-product-selection-guide.pdf. XMP452. Version: v1.0.1, 2018
|
| [26] |
UltraScale architecture DSP slice user guide. https://www.xilinx.com/support/documentation/user_guides/ug579-ultrascale-dsp.pdf. UG579. Version: v1.9, September 20, 2019
|
| [27] |
Langhammer M, Pasca B. Floating-point DSP block architecture for FPGAs. The 2015 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2015, 117
|
| [28] |
Intel? AgilexTM FPGA advanced information brief. https://www.intel.com/content/dam/www/programmable/us/en/pdfs/literature/hb/agilex/ag-overview.pdf. AG-OVERVIEW Version: 2019.07.02
|
 WeChat ID
WeChat ID
Journal of Semiconductors © 2017 All Rights Reserved 京ICP備05085259號(hào)-2

